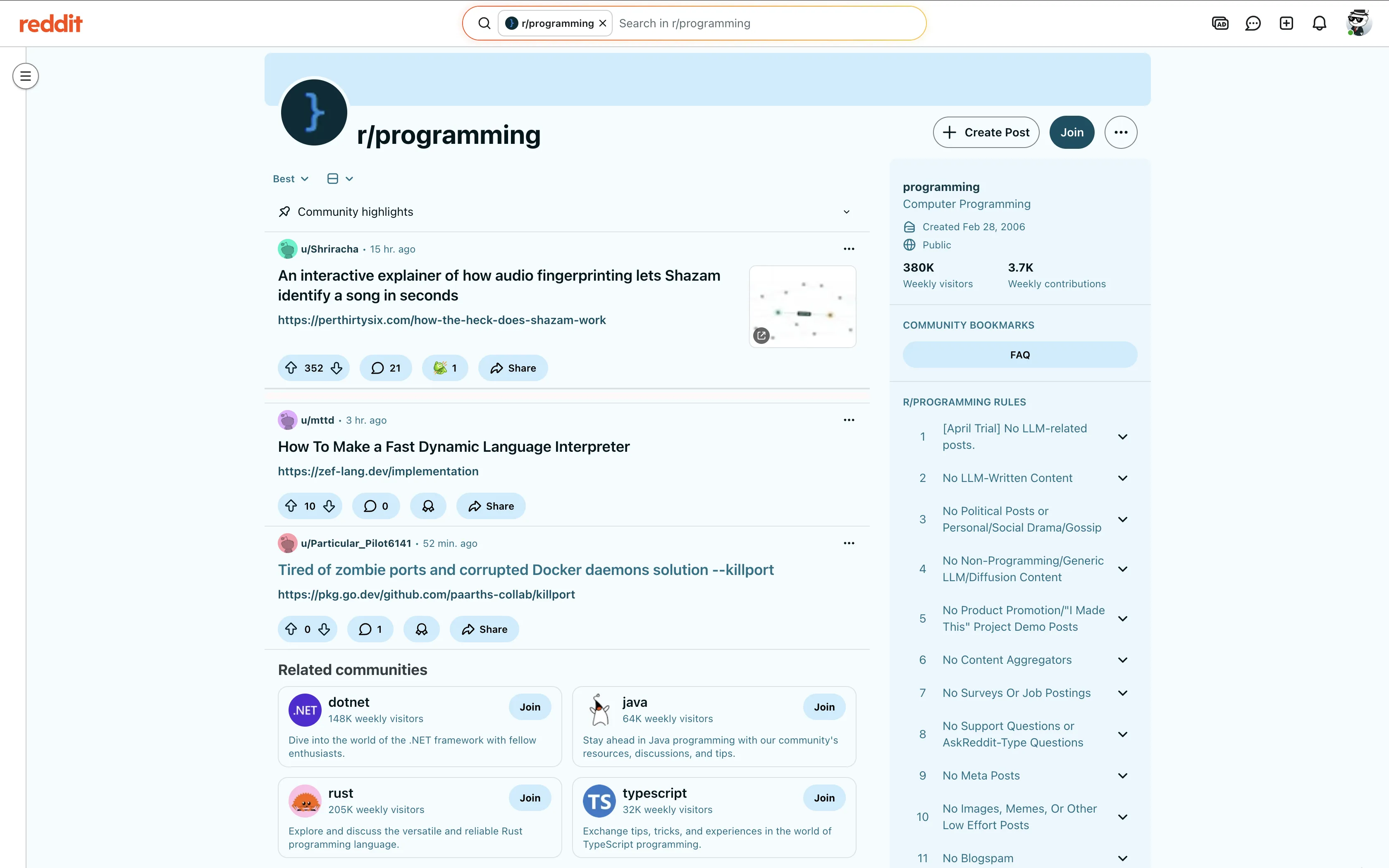
Where does your training data come from? If you're building sentiment analysis, trend detection, or any NLP pipeline, the answer is probably Reddit. Millions of posts, organized by topic, scored by community votes, and threaded with multi-level comments. It's one of the richest public text datasets on the internet.
The catch: Reddit doesn't want you scraping it. Their API costs money now, PRAW has rate limits that make large-scale collection painful, and hitting reddit.com directly with a datacenter IP gets you a "whoa there, pardner!" block page. Reddit also serves a JavaScript challenge on every page load, which means plain HTTP libraries like Requests return an empty shell instead of content.
This guide solves all three problems. We'll use a cloud browser API with residential proxies that passes Reddit's JS challenge automatically, extracts structured post data as JSON, and reads full comment threads as clean markdown. One API call for subreddit feeds, one more for post details.
What you'll build:
- A working Reddit scraper that extracts post titles, scores, authors, and comment counts
- Subreddit feed extraction with configurable result limits
- Post detail page scraping with full comment threads
- A "subreddit monitor" that detects new posts since your last check
- CSV and JSON export for the extracted data
- JavaScript challenge bypass that works without any extra configuration
TL;DR: Scrape Reddit posts, comments, and scores with Browserbeam's API using residential proxies. Reddit's JavaScript challenge passes automatically. Define an extraction schema for structured JSON, or use observe for full markdown including comment threads. Works on any public subreddit.
Quick Start: Scrape 25 Reddit Posts in Seconds
Here's a complete Reddit scraper. It pulls five posts from r/programming, returns structured JSON, and closes the session. One HTTP request.
Don't have an API key yet? Create a free Browserbeam account — you get 5,000 credits, no credit card required.
SID=$(curl -s -X POST https://api.browserbeam.com/v1/sessions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://www.reddit.com/r/programming/",
"proxy": { "kind": "residential", "country": "us" },
"block_resources": ["image", "font", "media"]
}' | jq -r '.session_id') && sleep 5 && \
curl -s -X POST "https://api.browserbeam.com/v1/sessions/$SID/act" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"steps": [
{
"extract": {
"posts": [{
"_parent": "article[data-post-id]",
"_limit": 25,
"title": "a[slot=title] >> text",
"url": "a[slot=title] >> href",
"author": "shreddit-post >> author",
"score": "shreddit-post >> score",
"comment_count": "shreddit-post >> comment-count"
}]
}
},
{ "close": {} }
]
}' | jq '.extraction'from browserbeam import Browserbeam
client = Browserbeam(api_key="YOUR_API_KEY")
session = client.sessions.create(
url="https://www.reddit.com/r/programming/",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
result = session.extract(
posts=[{
"_parent": "article[data-post-id]",
"_limit": 25,
"title": "a[slot='title'] >> text",
"url": "a[slot='title'] >> href",
"author": "shreddit-post >> author",
"score": "shreddit-post >> score",
"comment_count": "shreddit-post >> comment-count",
}]
)
session.close()
for post in result.extraction["posts"]:
print(f"[{post['score']}] {post['title'][:60]}... ({post['comment_count']} comments)")import Browserbeam from "browserbeam";
const client = new Browserbeam({ apiKey: "YOUR_API_KEY" });
const session = await client.sessions.create({
url: "https://www.reddit.com/r/programming/",
proxy: { kind: "residential", country: "us" },
block_resources: ["image", "font", "media"],
});
await session.wait({ selector: "shreddit-post" });
const result = await session.extract({
posts: [{
_parent: "article[data-post-id]",
_limit: 25,
title: "a[slot='title'] >> text",
url: "a[slot='title'] >> href",
author: "shreddit-post >> author",
score: "shreddit-post >> score",
comment_count: "shreddit-post >> comment-count",
}],
});
await session.close();
for (const post of result.extraction!.posts as any[]) {
console.log(`[${post.score}] ${post.title.slice(0, 60)}... (${post.comment_count} comments)`);
}require "browserbeam"
client = Browserbeam::Client.new(api_key: "YOUR_API_KEY")
session = client.sessions.create(
url: "https://www.reddit.com/r/programming/",
proxy: { kind: "residential", country: "us" },
block_resources: ["image", "font", "media"]
)
session.wait(selector: "shreddit-post")
result = session.extract(
"posts" => [{
"_parent" => "article[data-post-id]",
"_limit" => 25,
"title" => "a[slot='title'] >> text",
"url" => "a[slot='title'] >> href",
"author" => "shreddit-post >> author",
"score" => "shreddit-post >> score",
"comment_count" => "shreddit-post >> comment-count"
}]
)
session.close
result.extraction["posts"].each do |post|
puts "[#{post['score']}] #{post['title'][0..59]}... (#{post['comment_count']} comments)"
endThat returns structured JSON with 25 posts:
{
"posts": [
{
"title": "An interactive explainer of how audio fingerprinting lets Shazam identify a song in seconds",
"url": "https://www.reddit.com/r/programming/comments/1sqrv8p/an_interactive_explainer_of_how_audio/",
"author": "Shriracha",
"score": "384",
"comment_count": "23"
},
{
"title": "The API Tooling Crisis: Why developers are abandoning Postman and its clones?",
"url": "https://www.reddit.com/r/programming/comments/1smyun6/the_api_tooling_crisis_why_developers_are/",
"author": "Successful_Bowl2564",
"score": "645",
"comment_count": "380"
},
{
"title": "I Decompiled the White House's New App",
"url": "https://www.reddit.com/r/programming/comments/1s6b9zt/i_decompiled_the_white_houses_new_app/",
"author": "CackleRooster",
"score": "2667",
"comment_count": "265"
}
]
}Reddit serves a JavaScript challenge on every page load that triggers a browser redirect. Unlike Amazon or eBay, you can't use a single one-shot request with Reddit. The two-step approach (create session, then act) gives the JS challenge time to resolve before extraction runs. The sleep 5 in the cURL example and the session.wait(selector: "shreddit-post") in the SDKs both ensure the page is fully loaded with 25+ posts before extraction. No CAPTCHA solving. No PRAW rate limits. No JavaScript rendering headaches. The rest of this guide explains how each piece works, why residential proxies matter for Reddit, and how to scrape full post detail pages with comment threads.
What Data Can You Extract from Reddit?
Reddit organizes content into subreddit feeds and individual post pages. Each carries different data.
Subreddit Feeds vs Post Detail Pages
Subreddit feeds (/r/{subreddit}/) show a list of posts sorted by hot, new, top, or rising. Each post card has a title, author, score (upvotes minus downvotes), comment count, post age, and a link to the full post.
Post detail pages (/r/{subreddit}/comments/{id}/) contain the full post body (text, links, or embedded media), the complete comment thread with nested replies, author flairs, and individual comment scores. This is where the rich text data lives.
| Category | Fields | Available On |
|---|---|---|
| Post identity | Title, URL, post ID, subreddit | Feed + Detail |
| Engagement | Score, comment count, upvote ratio | Feed + Detail |
| Author | Username, flair, account age | Feed + Detail |
| Content | Post body text, linked URL, media | Detail only |
| Comments | Comment text, author, score, nesting depth | Detail only |
Sample Data: Subreddit Feed (Extract)
{
"title": "Things you didn't know about (Postgres) indexes",
"url": "https://www.reddit.com/r/programming/comments/1snb3gi/things_you_didnt_know_about_postgres_indexes/",
"author": "NotTreeFiddy",
"score": "245",
"comment_count": "38"
}Sample Data: Post Detail Page (Observe)
# Announcement: Temporary LLM Content Ban
**r/programming** 20d ago | **ChemicalRascal**
Hey folks,
After a lot of discussion, we've decided to trial a ban of any and all content
relating to LLMs. We get a lot of posts related to LLMs and typically they are
not in line with what we want the subreddit to be...
---
**terablast** 20d ago
*looks at calendar* hmm
1.1K upvotes
**Humble_Standard3860** 20d ago
was wondering when someone would notice the timing lol
272 upvotesThe observe endpoint captures the post body, comment text, vote counts, author names, and relative timestamps in clean markdown. For NLP and sentiment analysis, this is the format you want.
Why Reddit Blocks Datacenter Proxies (and How Residential Fixes It)
This is the section that matters most if you've tried scraping Reddit before and failed. Reddit uses two layers of defense: IP reputation and a JavaScript challenge.
The Datacenter Block
Reddit maintains blocklists of IP ranges from AWS, GCP, Azure, and hosting providers. When a request comes from a datacenter IP, Reddit returns a block page:
You've been blocked by network security.
To continue, log in to your Reddit account or use your developer tokenWe tested this directly. Datacenter proxy with the same Browserbeam configuration returned this block page 100% of the time. Residential proxy with identical settings loaded the full subreddit feed on every attempt.
| Proxy Type | Reddit Success Rate | Block Message | Cost |
|---|---|---|---|
| Datacenter | 0% (blocked) | "blocked by network security" | Low |
| Residential | ~98% | None (JS challenge auto-passes) | Higher |
The JavaScript Challenge
Even with residential proxies, Reddit serves a JavaScript challenge on every page load. You'll see a URL with ?solution=...&js_challenge=1&token=... parameters. A cloud browser with residential IP passes this challenge automatically. The page loads, the challenge resolves, and you get the full rendered content.
Plain HTTP libraries (Requests, curl without a browser) can't execute JavaScript at all. That's why PRAW exists: it uses Reddit's API instead of scraping the website. But PRAW has rate limits (100 requests per minute for OAuth apps) and Reddit's API pricing makes large-scale collection expensive.
Why This Matters for Your Scraper
If you're using any scraping approach on Reddit, you need both:
- Residential proxy to pass the IP reputation check
- A real browser (or cloud browser) to execute the JavaScript challenge
Browserbeam handles both. Set proxy: { kind: "residential" } and the rest happens automatically. No challenge-solving code, no proxy rotation, no headless browser detection workarounds.
Scraping Subreddit Feeds
Let's build the subreddit scraper step by step.
Step 1: One-Shot Extract with Close
Reddit wraps each post in an <article> element containing a <shreddit-post> custom element. The shreddit-post tag carries metadata as HTML attributes: author, score, comment-count. The title and URL live inside a child <a> element with slot="title". We use article[data-post-id] as the parent selector to match real posts and skip ad banners.
SID=$(curl -s -X POST https://api.browserbeam.com/v1/sessions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://www.reddit.com/r/technology/",
"proxy": { "kind": "residential", "country": "us" },
"block_resources": ["image", "font", "media"]
}' | jq -r '.session_id') && sleep 5 && \
curl -s -X POST "https://api.browserbeam.com/v1/sessions/$SID/act" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"steps": [
{
"extract": {
"posts": [{
"_parent": "article[data-post-id]",
"_limit": 25,
"title": "a[slot=title] >> text",
"url": "a[slot=title] >> href",
"author": "shreddit-post >> author",
"score": "shreddit-post >> score",
"comment_count": "shreddit-post >> comment-count"
}]
}
},
{ "close": {} }
]
}' | jq '.extraction'from browserbeam import Browserbeam
client = Browserbeam(api_key="YOUR_API_KEY")
session = client.sessions.create(
url="https://www.reddit.com/r/technology/",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
result = session.extract(
posts=[{
"_parent": "article[data-post-id]",
"_limit": 25,
"title": "a[slot='title'] >> text",
"url": "a[slot='title'] >> href",
"author": "shreddit-post >> author",
"score": "shreddit-post >> score",
"comment_count": "shreddit-post >> comment-count",
}]
)
session.close()
posts = result.extraction["posts"]
print(f"Extracted {len(posts)} posts from r/technology")import Browserbeam from "browserbeam";
const client = new Browserbeam({ apiKey: "YOUR_API_KEY" });
const session = await client.sessions.create({
url: "https://www.reddit.com/r/technology/",
proxy: { kind: "residential", country: "us" },
block_resources: ["image", "font", "media"],
});
await session.wait({ selector: "shreddit-post" });
const result = await session.extract({
posts: [{
_parent: "article[data-post-id]",
_limit: 25,
title: "a[slot='title'] >> text",
url: "a[slot='title'] >> href",
author: "shreddit-post >> author",
score: "shreddit-post >> score",
comment_count: "shreddit-post >> comment-count",
}],
});
await session.close();
const posts = result.extraction!.posts as any[];
console.log(`Extracted ${posts.length} posts from r/technology`);require "browserbeam"
client = Browserbeam::Client.new(api_key: "YOUR_API_KEY")
session = client.sessions.create(
url: "https://www.reddit.com/r/technology/",
proxy: { kind: "residential", country: "us" },
block_resources: ["image", "font", "media"]
)
session.wait(selector: "shreddit-post")
result = session.extract(
"posts" => [{
"_parent" => "article[data-post-id]",
"_limit" => 25,
"title" => "a[slot='title'] >> text",
"url" => "a[slot='title'] >> href",
"author" => "shreddit-post >> author",
"score" => "shreddit-post >> score",
"comment_count" => "shreddit-post >> comment-count"
}]
)
session.close
posts = result.extraction["posts"]
puts "Extracted #{posts.length} posts from r/technology"The _parent selector article[data-post-id] matches the <article> wrapper around each Reddit post. The data-post-id attribute filters out non-post elements like ad banners. Inside each article, the shreddit-post custom element carries metadata as HTML attributes: author, score, and comment-count. The >> attribute syntax reads these directly from the element.
Reddit serves a JavaScript challenge on every page load that triggers a browser redirect. Unlike most sites, you can't use a single one-shot request. The two-step approach (create session, then act) gives the JS challenge time to resolve. The session.wait(selector: "shreddit-post") call in the SDKs blocks server-side until post elements are in the DOM. In our testing, this returned 25 posts in under 15 seconds with a residential proxy.
Step 2: Sort by New, Top, or Rising
Reddit supports different sort orders through URL paths. Append /new/, /top/, or /rising/ to the subreddit URL:
from browserbeam import Browserbeam
client = Browserbeam(api_key="YOUR_API_KEY")
schema = {
"posts": [{
"_parent": "article[data-post-id]",
"_limit": 15,
"title": "a[slot='title'] >> text",
"url": "a[slot='title'] >> href",
"author": "shreddit-post >> author",
"score": "shreddit-post >> score",
}]
}
sort_orders = ["hot", "new", "top"]
results = {}
for sort in sort_orders:
suffix = f"/{sort}/" if sort != "hot" else "/"
session = client.sessions.create(
url=f"https://www.reddit.com/r/programming{suffix}",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
result = session.extract(**schema)
session.close()
results[sort] = result.extraction["posts"]
print(f"{sort}: {len(results[sort])} posts")
for sort, posts in results.items():
top = posts[0] if posts else {}
print(f"\n{sort.upper()} #1: [{top.get('score', '?')}] {top.get('title', 'N/A')[:60]}")For top posts, you can also add a time filter: /top/?t=day, /top/?t=week, /top/?t=month, /top/?t=year, or /top/?t=all.
Using Observe for Richer Subreddit Data
The extract endpoint returns structured JSON, but the observe endpoint returns the full page as markdown. For Reddit, observe captures content that CSS selectors miss: post flairs, pinned status, external link URLs, and the "Community highlights" sidebar content.
SID=$(curl -s -X POST https://api.browserbeam.com/v1/sessions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://www.reddit.com/r/programming/",
"proxy": { "kind": "residential", "country": "us" },
"block_resources": ["image", "font", "media"]
}' | jq -r '.session_id') && sleep 5 && \
curl -s -X POST "https://api.browserbeam.com/v1/sessions/$SID/act" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{ "steps": [{ "observe": {} }, { "close": {} }] }' \
| jq -r '.page.markdown.content'from browserbeam import Browserbeam
client = Browserbeam(api_key="YOUR_API_KEY")
session = client.sessions.create(
url="https://www.reddit.com/r/programming/",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
result = session.observe()
session.close()
print(result.page.markdown.content)import Browserbeam from "browserbeam";
const client = new Browserbeam({ apiKey: "YOUR_API_KEY" });
const session = await client.sessions.create({
url: "https://www.reddit.com/r/programming/",
proxy: { kind: "residential", country: "us" },
block_resources: ["image", "font", "media"],
});
await session.wait({ selector: "shreddit-post" });
const result = await session.observe();
await session.close();
console.log(result.page?.markdown?.content);require "browserbeam"
client = Browserbeam::Client.new(api_key: "YOUR_API_KEY")
session = client.sessions.create(
url: "https://www.reddit.com/r/programming/",
proxy: { kind: "residential", country: "us" },
block_resources: ["image", "font", "media"]
)
session.wait(selector: "shreddit-post")
result = session.observe
session.close
puts result.page.markdown.contentThe markdown output includes post titles, authors, timestamps, external URLs, and vote counts in a human-readable format. For feeding data into an LLM or building an AI-powered content aggregator, observe is often the better choice because the output goes directly into a prompt without JSON parsing.
Scraping Post Detail Pages
Post detail pages are where the real data lives: the full post body and the entire comment thread. Unlike eBay (where detail pages crash), Reddit detail pages load reliably with residential proxies.
Extracting a Single Post with Comments
For post detail pages, observe is the recommended approach. Reddit's comment threads are deeply nested with varying structures (collapsed threads, "Continue this thread" links, moderator comments). CSS selectors would need to handle dozens of edge cases. The observe endpoint reads the rendered page and returns everything as structured markdown.
from browserbeam import Browserbeam
client = Browserbeam(api_key="YOUR_API_KEY")
session = client.sessions.create(
url="https://www.reddit.com/r/programming/comments/1s9jkzi/announcement_temporary_llm_content_ban/",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
result = session.observe()
session.close()
markdown = result.page.markdown.content
print(f"Post content length: {len(markdown)} characters")
print(markdown[:500])The output includes the post title, author, body text, and the top-level comments with their scores and authors. Reddit loads a subset of comments by default (typically 20-50 top comments). For posts with hundreds of comments, you'll get the most upvoted ones.
Building a Feed-to-Detail Pipeline
The real power comes from combining feed extraction with detail page scraping. Pull post URLs from the subreddit, then visit each one for full content:
from browserbeam import Browserbeam
client = Browserbeam(api_key="YOUR_API_KEY")
session = client.sessions.create(
url="https://www.reddit.com/r/programming/new/",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
feed = session.extract(
posts=[{
"_parent": "article[data-post-id]",
"_limit": 5,
"title": "a[slot='title'] >> text",
"url": "a[slot='title'] >> href",
"score": "shreddit-post >> score",
}]
)
detailed_posts = []
for post in feed.extraction["posts"]:
post_url = post["url"]
if not post_url.startswith("http"):
post_url = f"https://www.reddit.com{post_url}"
session.goto(post_url)
result = session.observe()
detailed_posts.append({
"title": post["title"],
"score": post["score"],
"content": result.page.markdown.content,
})
session.close()
for p in detailed_posts:
print(f"\n{'='*60}")
print(f"[{p['score']}] {p['title'][:60]}")
print(f"Content preview: {p['content'][:200]}...")This uses a single session for the entire pipeline. The browser keeps its cookies and residential IP between navigations, which looks like a real user clicking through posts. (Pro tip: add a 1-2 second delay between navigations if you're scraping many posts. Reddit's rate limiting is lenient, but it exists.)
Building a Subreddit Monitor
Here's a practical project: a script that checks a subreddit for new posts and logs anything that appeared since your last check. Run it on a schedule (cron, GitHub Actions, or a task queue) to build a real-time feed.
import json
import os
from datetime import datetime
from browserbeam import Browserbeam
STATE_FILE = "subreddit_monitor_state.json"
def load_state():
if os.path.exists(STATE_FILE):
with open(STATE_FILE) as f:
return json.load(f)
return {"seen_urls": []}
def save_state(state):
with open(STATE_FILE, "w") as f:
json.dump(state, f, indent=2)
def check_subreddit(subreddit, limit=20):
client = Browserbeam(api_key=os.environ["BROWSERBEAM_API_KEY"])
state = load_state()
session = client.sessions.create(
url=f"https://www.reddit.com/r/{subreddit}/new/",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
result = session.extract(
posts=[{
"_parent": "article[data-post-id]",
"_limit": limit,
"title": "a[slot='title'] >> text",
"url": "a[slot='title'] >> href",
"author": "shreddit-post >> author",
"score": "shreddit-post >> score",
}]
)
session.close()
new_posts = []
for post in result.extraction["posts"]:
if post["url"] not in state["seen_urls"]:
new_posts.append(post)
state["seen_urls"].append(post["url"])
state["seen_urls"] = state["seen_urls"][-500:]
save_state(state)
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M")
print(f"[{timestamp}] r/{subreddit}: {len(new_posts)} new posts")
for post in new_posts:
print(f" [{post['score']}] {post['title'][:70]}")
print(f" by u/{post['author']} | {post['url']}")
return new_posts
check_subreddit("programming")The script keeps a JSON file with URLs it has already seen. On each run, it compares the current feed against the state file and reports only new posts. The seen_urls list is capped at 500 entries to prevent the file from growing indefinitely.
For production use, swap the JSON file for a database (SQLite or PostgreSQL) and add a notification layer (Slack webhook, email, or Discord bot).
Saving and Exporting Your Data
Once you've extracted Reddit post data, here's how to save it for analysis.
Export to CSV
import csv
def save_posts_csv(posts, filename="reddit_posts.csv"):
if not posts:
return
fieldnames = ["title", "url", "author", "score", "comment_count"]
with open(filename, "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames, extrasaction="ignore")
writer.writeheader()
writer.writerows(posts)
print(f"Saved {len(posts)} posts to {filename}")
save_posts_csv(result.extraction["posts"])Export to JSON
import json
def save_posts_json(posts, filename="reddit_posts.json"):
with open(filename, "w", encoding="utf-8") as f:
json.dump(posts, f, indent=2, ensure_ascii=False)
print(f"Saved {len(posts)} posts to {filename}")
save_posts_json(result.extraction["posts"])Saving Comment Threads (Observe Output)
For post detail pages where you used observe, the content is markdown text rather than structured JSON. Save it as a .md file or parse it with a markdown library:
def save_post_markdown(title, content, output_dir="reddit_posts"):
os.makedirs(output_dir, exist_ok=True)
slug = title.lower()[:50].replace(" ", "_").replace("/", "_")
filename = os.path.join(output_dir, f"{slug}.md")
with open(filename, "w", encoding="utf-8") as f:
f.write(content)
print(f"Saved to {filename}")For production pipelines, store structured data (from extract) in a database and raw content (from observe) in object storage or a document database. The scaling web automation guide covers scheduling and storage patterns in detail.
DIY Reddit Scraping vs Browserbeam API
Let's compare the Browserbeam approach with the two most common DIY methods: PRAW (Reddit's official Python wrapper) and plain HTTP scraping.
The PRAW Approach
import praw
reddit = praw.Reddit(
client_id="YOUR_CLIENT_ID",
client_secret="YOUR_CLIENT_SECRET",
user_agent="my_scraper/1.0",
)
subreddit = reddit.subreddit("programming")
for post in subreddit.hot(limit=10):
print(f"[{post.score}] {post.title[:60]}")
print(f" by u/{post.author} | {post.num_comments} comments")PRAW works well for small-scale data collection. But it uses Reddit's API, which has limits: 100 requests per minute for OAuth apps, and Reddit's API pricing (introduced in 2023) makes high-volume collection expensive.
The Requests + BeautifulSoup Approach
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36",
}
response = requests.get(
"https://www.reddit.com/r/programming/",
headers=headers,
)
soup = BeautifulSoup(response.text, "html.parser")
posts = soup.find_all("shreddit-post")
for post in posts[:5]:
title_link = post.find("a", slot="title")
title = title_link.text.strip() if title_link else "N/A"
author = post.get("author", "N/A")
print(f"[{post.get('score', '?')}] {title[:60]} by u/{author}")This fails on Reddit. The requests.get() call returns HTML with a JavaScript challenge page, not the rendered subreddit content. The shreddit-post elements don't exist in the server-rendered HTML because they're web components that require JavaScript execution.
Side-by-Side Comparison
| Factor | PRAW (API) | DIY (BeautifulSoup) | Browserbeam API |
|---|---|---|---|
| Works on Reddit | Yes (via API) | No (JS challenge) | Yes (cloud browser) |
| Comment threads | Yes (full depth) | No | Yes (via observe) |
| Rate limits | 100 req/min | N/A (blocked) | Per credit budget |
| Setup | OAuth app registration, API keys | Headers, proxy | SDK install, API key |
| Output format | Python objects | N/A | JSON or markdown |
| Cost | Reddit API pricing | Free (but broken) | Per session credits |
| Multi-language | Python only | Python only | cURL, Python, TS, Ruby |
| No API registration | No (requires Reddit app) | Yes | Yes |
When PRAW Still Makes Sense
If you need comment-level data at small scale (under 100 requests per minute) and already have a Reddit API app registered, PRAW is simpler. For larger collection, cross-subreddit scraping, or when you want the rendered page content (not just API data), the browser approach avoids Reddit's API limits entirely.
Real-World Reddit Scraping Use Cases
1. Sentiment Analysis for Product Launches
Track how a subreddit reacts to a product launch or major announcement. Extract posts and comments, then feed the text through a sentiment classifier:
from browserbeam import Browserbeam
client = Browserbeam(api_key="YOUR_API_KEY")
def analyze_subreddit_sentiment(subreddit, query):
session = client.sessions.create(
url=f"https://www.reddit.com/r/{subreddit}/search/?q={query}&sort=new",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
result = session.observe()
session.close()
markdown = result.page.markdown.content
print(f"Collected {len(markdown)} chars from r/{subreddit} search for '{query}'")
return markdown
content = analyze_subreddit_sentiment("technology", "openai")Feed the markdown output into your LLM or sentiment analysis pipeline. The observe format works directly as input to OpenAI, Anthropic, or local models without any preprocessing.
2. Trend Detection Across Subreddits
Monitor multiple subreddits to spot emerging topics before they hit mainstream tech news:
def scan_trending_topics(subreddits, min_score=100):
trending = []
for sub in subreddits:
session = client.sessions.create(
url=f"https://www.reddit.com/r/{sub}/rising/",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
result = session.extract(
posts=[{
"_parent": "article[data-post-id]",
"_limit": 10,
"title": "a[slot='title'] >> text",
"score": "shreddit-post >> score",
"comment_count": "shreddit-post >> comment-count",
}]
)
session.close()
for post in result.extraction["posts"]:
score = int(post.get("score", "0") or "0")
if score >= min_score:
trending.append({**post, "subreddit": sub})
trending.sort(key=lambda p: int(p.get("score", "0") or "0"), reverse=True)
for post in trending[:10]:
print(f"r/{post['subreddit']} [{post['score']}] {post['title'][:60]}")
return trending
scan_trending_topics(["programming", "technology", "machinelearning", "webdev"])The /rising/ sort surfaces posts that are gaining traction quickly. Combined with a score threshold, this catches topics in the early stages of going viral.
3. Content Aggregation for NLP Datasets
Build a text dataset from Reddit for training or fine-tuning language models. Extract post bodies and top comments from specific subreddits:
def collect_dataset(subreddit, num_posts=5):
session = client.sessions.create(
url=f"https://www.reddit.com/r/{subreddit}/top/?t=week",
proxy={"kind": "residential", "country": "us"},
block_resources=["image", "font", "media"],
)
session.wait(selector="shreddit-post")
feed = session.extract(
posts=[{
"_parent": "article[data-post-id]",
"_limit": num_posts,
"title": "a[slot='title'] >> text",
"url": "a[slot='title'] >> href",
}]
)
dataset = []
for post in feed.extraction["posts"]:
post_url = post["url"]
if not post_url.startswith("http"):
post_url = f"https://www.reddit.com{post_url}"
session.goto(post_url)
detail = session.observe()
dataset.append({
"title": post["title"],
"url": post_url,
"content": detail.page.markdown.content,
})
session.close()
print(f"Collected {len(dataset)} posts with full content from r/{subreddit}")
return dataset
data = collect_dataset("askscience", num_posts=5)This pattern uses a single session for efficiency: extract URLs from the feed, then navigate to each post for the full content. The observe output includes both the post body and comments, giving you conversational text data that's valuable for fine-tuning.
Common Mistakes When Scraping Reddit
1. Using Datacenter Proxies
The most common failure mode. Reddit blocks datacenter IPs with a "blocked by network security" page. There's no workaround, no header trick, no retry strategy that fixes this. You need residential proxies.
Fix: Set proxy: { kind: "residential", country: "us" } in your session configuration. The cost per session is higher, but the success rate goes from 0% to ~98%.
2. Expecting Server-Rendered HTML
Reddit uses web components (shreddit-post) that require JavaScript execution. Libraries like Requests and urllib get an empty HTML shell with a JavaScript challenge. BeautifulSoup can't parse what doesn't exist in the server response.
Fix: Use a cloud browser (Browserbeam, Playwright, Puppeteer) that executes JavaScript. Browserbeam handles this automatically.
3. Ignoring the Observe Endpoint for Comments
Trying to extract comment threads with CSS selectors is painful. Reddit nests comments with varying depth, collapsed threads, "Continue this thread" links, and moderator-distinguished comments. The DOM structure changes based on how many comments are loaded.
Fix: Use observe for post detail pages. The markdown output captures the comment tree in a readable format without any selectors.
4. Extracting Before the JavaScript Challenge Resolves
Reddit serves a JavaScript challenge on every page load. The browser solves it automatically, but it triggers a page redirect. If you pack all your steps into a single one-shot sessions.create call, the challenge can destroy the execution context mid-redirect, returning null or only 3 posts instead of 25.
Fix: Use the two-step approach: create the session first (without steps), then call session.wait(selector="shreddit-post") followed by session.extract(...). The session creation gives the JS challenge time to resolve, and the wait call confirms posts are in the DOM before extraction runs. For cURL, use sessions.create + sleep 5 + sessions/{id}/act.
5. Not Filtering Promoted Posts
Reddit mixes sponsored content ("Promoted" posts) into the feed. These show up as shreddit-post elements with the same structure as organic posts, but they link to advertiser pages instead of Reddit discussions.
Fix: Filter by URL pattern after extraction. Organic Reddit posts have URLs matching /r/{subreddit}/comments/. Promoted posts link to external advertiser domains or contain rpAd in their attributes.
6. Scraping While Logged In
Scraping from an authenticated Reddit account risks getting that account permanently banned. Reddit's terms of service explicitly prohibit automated data collection, and they enforce it more aggressively on authenticated sessions.
Fix: Always scrape without logging in. Public subreddit data is accessible without authentication through a cloud browser with residential proxies. You get the same content a logged-out visitor sees.
Frequently Asked Questions
Is it legal to scrape Reddit posts?
Reddit's Terms of Service prohibit scraping and automated data collection. However, scraping publicly visible posts and comments falls under the same legal framework as other public web data. The hiQ Labs v. LinkedIn ruling (2022) established that accessing publicly available data doesn't violate the Computer Fraud and Abuse Act. Reddit introduced API pricing in 2023 and sued some third-party apps, but enforcement against individual scrapers has been limited to technical blocking (IP bans, JS challenges) rather than litigation. Consult a lawyer for commercial applications.
How do I scrape Reddit with Python?
Install the Browserbeam Python SDK with pip install browserbeam. Create a client with your API key and call sessions.create() with a subreddit URL and residential proxy. Then call session.wait(selector="shreddit-post") to let the JavaScript challenge resolve, followed by session.extract(...) with your schema. See the Quick Start section for a working example.
Does Reddit block web scrapers?
Yes. Reddit blocks datacenter IP ranges with a "blocked by network security" page and serves a JavaScript challenge on every page load. Residential proxies bypass the IP block, and a cloud browser (like Browserbeam) handles the JavaScript challenge automatically. Plain HTTP libraries like Requests cannot scrape Reddit because they can't execute JavaScript.
What is the best Reddit scraper in 2026?
For structured data extraction with JavaScript rendering and built-in residential proxies, a cloud browser API like Browserbeam handles Reddit reliably. For small-scale collection (under 100 requests/minute) with an existing Reddit app, PRAW is simpler but subject to Reddit's API pricing. For teams running their own Playwright setup, adding residential proxy rotation gets you most of the way, but you're maintaining the infrastructure.
Can I scrape Reddit comments and replies?
Yes. Navigate to a post URL and use the observe endpoint to get the full comment thread as structured markdown. Reddit loads the top 20-50 comments by default. For posts with hundreds of comments, you'll get the highest-voted threads. The markdown output preserves comment nesting, author names, scores, and timestamps.
Reddit scraper vs Reddit API: which is better?
Reddit's official API (via PRAW or direct HTTP) gives you structured data with deep comment access, but it requires OAuth app registration, has rate limits (100 req/min), and costs money at scale since the 2023 pricing changes. Web scraping with a cloud browser avoids API registration and rate limits, works in any language, and extracts the rendered page content. The tradeoff is that scraping costs per-session credits instead of per-API-call pricing. For cross-subreddit monitoring or large dataset collection, scraping is typically more cost-effective.
How do I scrape Reddit without getting blocked?
Two things matter on Reddit: residential proxies (not datacenter) and a real browser that executes JavaScript. Datacenter IPs are blocked 100% of the time. Residential proxies pass the IP check, and a cloud browser handles the JavaScript challenge automatically. Resource blocking (["image", "font", "media"]) speeds up page loads without affecting content extraction.
Can I scrape multiple subreddits at once?
Yes. Create a separate session for each subreddit or use a single session with goto() to navigate between subreddits. For one-shot scrapes (extract + close), create parallel sessions for better throughput. For pipelines that need to maintain state across pages, use goto() within a single session and call session.close() when finished.
Start Scraping Reddit Today
We covered the full stack: extracting subreddit feeds with CSS selectors, reading post detail pages with observe, bypassing Reddit's JavaScript challenge with residential proxies, building a subreddit monitor, and exporting data in CSV, JSON, and markdown formats.
The key insight for Reddit: residential proxies and a real browser are non-negotiable. Datacenter IPs get blocked, HTTP libraries get JavaScript challenge pages, and Reddit's API has rate limits that slow down large-scale collection. A cloud browser with residential proxy handles all three problems.
Try changing the subreddit in the Quick Start example. Replace r/programming with your target subreddit. Point the detail page scraper at a specific post URL. Adjust the _limit to pull more results. The extraction schema works the same way across all public subreddits.
For the complete API reference, check the Browserbeam documentation. The structured web scraping guide goes deeper on extraction schemas and the observe/extract tradeoff. If you're aggregating news alongside Reddit, the news scraping guide covers publisher section and article extraction. If you're building an AI agent that monitors Reddit for research, the web scraping agent tutorial shows how to wire up the full pipeline.